Usando modelos pre-entrenados en consola
Este blog se enfoca en los modelos pre entrenados que encontraremos en PyTorch para soluciones de aprendizaje profundo. Estos modelos pree-ntrenados son útiles ya que se han entrenado previamente en grandes conjuntos de datos y se han optimizado para tareas específicas. El blog explora las ventajas de usar estos modelos pre-entrenados y proporciona algunos ejemplos de su uso en diferentes aplicaciones.
Algunos de los modelos mas populares para el trabajo con imágenes y que ya vienen cargados son:
ResNet: Una red neuronal profunda para clasificación de imágenes que puede tener hasta 152 capas y ha sido entrenada en grandes conjuntos de datos como ImageNet.
VGG: Un modelo de clasificación de imágenes con varias variantes que varían en el número de capas, siendo VGG-16 y VGG-19 las más conocidas. También se entrenó en el conjunto de datos ImageNet.
AlexNet: Un modelo pionero de redes neuronales profundas que se utilizó para ganar el desafío ImageNet en 2012.
SqueezeNet: Un modelo que tiene una arquitectura pequeña y rápida para la clasificación de imágenes con buena precisión.
Lo que vamos a realizar en esta ocasión es un poco mas que solo invocar los modelos que ya están pre definidos en PyTorch. Vamos a generar un script que nos permitirá usar estos modelos para clasificar imágenes con distintas capas de salida.
Primeros pasos
Lo primero como siempre sera importar las librerías que vamos a utilizar. Y una breve descripción de que hace cada una:
- Todo lo que lleve torch en su nombre tiene que ver con la librería de deep learning que nos ayudara a generar y cargar los modelos.
- logging nos ayudara a llevar un registro de cada etapa (Debugging, información y errores).
- argparse la usaremos para configurar algunas variables de entrada al llamar el script.
- tqdm lo usaremos como para visualizar una barra de progreso.
import torch
import logging
import argparse
import torchvision
import torch.nn as nn
from tqdm import tqdm
import torch.optim as optim
from torchvision import models
import torch.utils.data as data
from torchvision import transforms
Vamos a generar una función para recibir los valores que podemos modificiar.
Hay que editar los últimos dos valores predeterminados con la ruta en donde se encuentran nuestros datos de entrenamiento y validación (DIR_DATA_ENT y DIR_DATA_VAL).
def get_args():
parser = argparse.ArgumentParser(description='Modelos pre-entrenados con pytorch')
parser.add_argument('--epochs', '-e', type=int, default=4, help='Numero de epocas')
parser.add_argument('--model', '-m', type=str, default='resnet50', help='Modelo a utilizar')
parser.add_argument('--batch_size', '-bs', type=int, default=32, help='Tamaño del batch')
parser.add_argument('--learning_rate', '-lr', type=float, default=1e-3, help='Learning rate', dest='lr')
parser.add_argument('--re_dim', '-rd', type=int, default=120, help='Re dimensionar las imagenes')
parser.add_argument('--clases', '-c', type=int, default=2, help='Numero de clases')
parser.add_argument('--neurons', '-n', type=int, default=500, help='Numero de capas')
parser.add_argument('--num_cap', '-nc', type=int, default=1, help='Numero de capas')
parser.add_argument('--ent_path', '-ep', type=str,
default= 'DIR_DATA_ENT',
help='Direccion de los datos de entrenamiento')
parser.add_argument('--val_path', '-cvp', type=str,
default= 'DIR_DATA_VAL',
help='Direccion de los datos de validacion')
return parser.parse_args()
Preprocesamiento de los datos
Ya que tenemos las variables editables así como sus valores predeterminados vamos a definir una función que tome nuestros datos de entrenamiento y validación: Los normalice, redimensione y convierta en tensores para después alimentar a nuestra red neuronal.
def creatingData(args):
trainDataPath = args.ent_path
valDataPath = args.val_path
transforms_images = transforms.Compose([
transforms.Resize((args.re_dim, args.re_dim)),
transforms.ToTensor(),
transforms.Normalize(mean= [0.485, 0.456, 0.406],
std= [0.229, 0.224, 0.225])
])
valData = torchvision.datasets.ImageFolder(root = valDataPath, transform = transforms_images)
trainData = torchvision.datasets.ImageFolder(root= trainDataPath, transform= transforms_images)
trainDataLoader= data.DataLoader(trainData, batch_size= args.batch_size, shuffle=True)
valDataLoader= data.DataLoader(valData, batch_size= args.batch_size, shuffle=True)
return trainDataLoader, valDataLoader
Ahora continuemos con una función importante si deseamos que nuestro script haga uso de la tarjeta gráfica de nuestro equipo (en caso de contar con una), también podemos realizar el entrenamiento desde algún servicio como Google Colab, en el cual podemos contratar GPUs o bien usar las que proporcionan de manera gratuita. Si no contamos con una GPU en nuestra PC el entrenamiento por defecto empleará el CPU. Usar el CPU en ocasiones es prácticamente imposible, ya que la inferencia y el entrenamiento tomaran una eternidad.
def checkingGPU():
if torch.cuda.is_available():
device = torch.device("cuda")
else:
device = torch.device("cpu")
logging.info(f'Using device {device}')
return device
Creando nuestra red neuronal convolucional
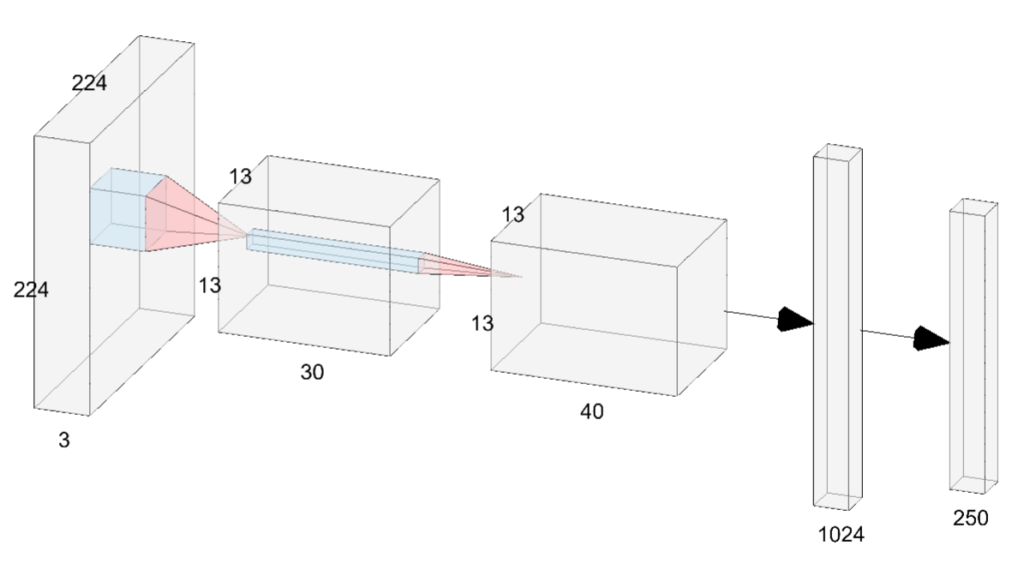
En este punto, vamos a definir la función encargada de generar la cantidad de neuronas que se asignará a cada capa del clasificador. Sin embargo, antes de continuar, haremos una breve pausa para explicar de manera sucinta las dos partes fundamentales de una red neuronal.
Una red convolucional artificial es una red neuronal profunda utilizada para procesar y clasificar imágenes (podemos ver un ejemplo en la siguiente imagen). Sus dos principales componentes son el extractor de características, que detecta patrones relevantes en la imagen (Los primeros tres elementos en nuestra imagen), y el clasificador, que utiliza estas características para clasificar la imagen en una categoría predefinida (los últimos dos elementos en nuestra imagen).
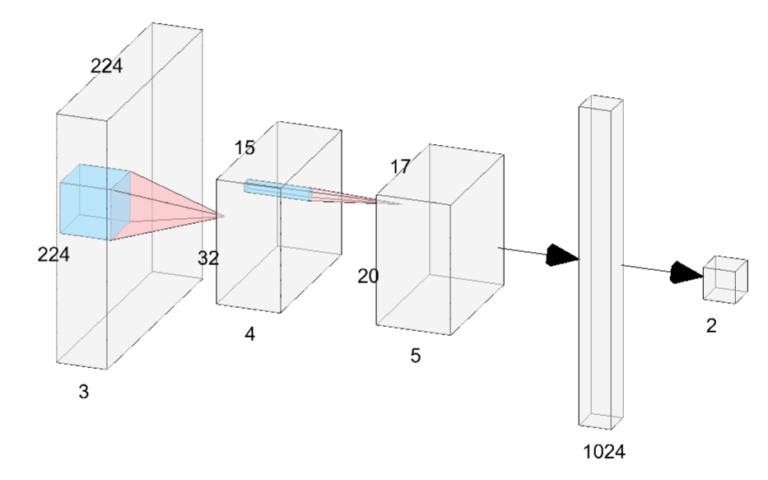
def getNeurons(nc):
ln = []
for i in range(nc):
ln.append(int(input(f'Layer {i} neurons: ')))
return ln
Ahora que hemos definido la función que determina la cantidad de neuronas en cada capa del clasificador, es momento de crear la función que se encarga de unir el extractor de características con el clasificador.
def trainingModel(model, output= 2, n_layers= 1, n_features= []):
transfer_model = model
layers = []
if n_layers > 1:
layers.append(nn.Linear(transfer_model.fc.in_features, n_features[0]))
for i in range(len(n_features)- 1):
layers.append(nn.Linear(n_features[i], n_features[i + 1]))
else:
layers.append(nn.Linear(transfer_model.fc.in_features, n_features[0]))
transfer_model.fc = nn.Sequential(*layers,
nn.ReLU(),
nn.Dropout(),
nn.Linear(n_features[-1], output),
nn.Softmax(dim= 0))
return transfer_model
A continuación, procederemos a crear una lista con los modelos disponibles que podemos seleccionar. Si así lo deseamos, podemos agregar más modelos, siempre y cuando PyTorch los tenga disponibles, el siguiente link puede darnos mas información de los modelos disponibles Models and pre-trained weights — Torchvision 0.15 documentation (pytorch.org). En caso de que el modelo que deseamos utilizar no se encuentre en la lista, se generará un mensaje de advertencia.
def menuDisplay(modelv):
preTrained = {'resnet50': models.resnet50,
'resnet101': models.resnet101,
'resnet152': models.resnet152,
'squeezenet1_0': models.squeezenet1_0,
'squeezenet1_1': models.squeezenet1_1,
'convnext_large': models.convnext_large,
'convnext_small': models.convnext_small,
'inception_v3': models.inception_v3,
'mobilenet_v3_large': models.inception_v3,
'googlenet': models.googlenet,
'efficientnet_b7': models.efficientnet_b7,
'efficientnet_b0': models.efficientnet_b0,
}
if modelv in preTrained.keys():
return preTrained[modelv](weights='DEFAULT')
else:
logging.error(f'No model found for {modelv}')
return None
Ya tenemos casi todo listo, nos falta la función que se va a encargar de entrenar nuestro modelo.
La siguiente función entrena nuestro modelo atreves de las épocas que seleccionemos, así como mostrarnos algunas métricas del desempeño del mismo modelo tanto en la parte de entrenamiento como en la validación del mismo. Mas adelante podemos hablar de la importancia de las métricas.
def train(model, optimizer, lossFn, trainLoader, valLoader, epochs, device, modelName):
best_model = 1000
for epoch in range(epochs):
trainingLoss = 0.0
trainingAcc = 0.0
totalt = 0
model.train()
for batch in tqdm(trainLoader, ncols= 70, desc= 'Training'):
optimizer.zero_grad()
inputs, targets = batch
inputs = inputs.to(device)
targets = targets.to(device)
output = model(inputs)
loss = lossFn(output, targets)
loss.backward()
optimizer.step()
trainingLoss += loss.item()
_, predicted = torch.max(output.data, 1)
trainingAcc += (predicted == targets).sum().item()
totalt += targets.size(0)
valLoss = 0.0
valAcc = 0.0
totalv = 0
model.eval()
with torch.no_grad():
for batch in tqdm(valLoader, ncols= 70, desc= 'Validating'):
inputs, targets = batch
inputs = inputs.to(device)
targets = targets.to(device)
output = model(inputs)
loss = lossFn(output, targets)
valLoss += loss.item()
_, predicted = torch.max(output.data, 1)
valAcc += (predicted == targets).sum().item()
totalv += targets.size(0)
if best_model > valAcc/totalv:
best_model = valAcc/totalv
torch.save(best_model, modelName + '_' + str(epoch) + '.pth')
print(f'Epoca: {epoch}, train_loss: {(trainingLoss/totalt):.4f}, train_acc: {(trainingAcc/totalt):.4f}')
print(f'Epoca: {epoch}, val_loss: {(valLoss/totalv):.4f}, val_acc: {(valAcc/totalv):.4f}')
print("------------------------------------")
Por último necesitamos una función que una y ejecute todo lo que ya codificamos, y nos vaya mostrando información de la configuración:
def main():
args = get_args()
logging.basicConfig(level=logging.INFO, format='%(levelname)s: %(message)s')
device = checkingGPU()
logging.info(f'''Starting training:
Model: {args.model}
N_Dense: {args.num_cap}
Epochs: {args.epochs}
Batch size: {args.batch_size}
Learning rate: {args.lr}
Images dimension: {args.re_dim}
Device: {device}
''')
n_features= getNeurons(args.num_cap) if args.num_cap > 1 else [args.neurons]
trainData, valData = creatingData(args)
model = trainingModel(menuDisplay(args.model), output = args.clases,
n_layers= args.num_cap,
n_features= n_features)
model.to(device)
optimizer = optim.SGD(model.parameters(), lr= args.lr, momentum=0.9)
loss= torch.nn.CrossEntropyLoss()
try:
train(model, optimizer, loss, trainData, valData, args.epochs, device, args.model)
except torch.cuda.OutOfMemoryError:
logging.error('Detected OutOfMemoryError! '
'Enabling checkpointing to reduce memory usage, but this slows down training. '
'Consider enabling AMP (--amp) for fast and memory efficient training')
torch.cuda.empty_cache()
Ahora solo falta llamar esa función main para poder probar nuestro script. Tambien lo pueden consultar de manera completa en el siguiente link:
if __name__ == '__main__':
main()
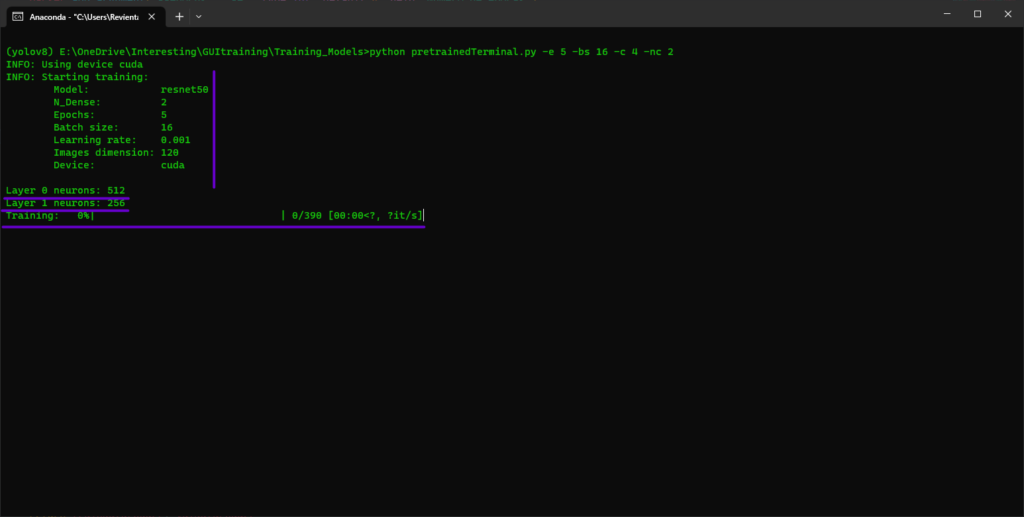
Vamos a probar los modelos pre-entrenados
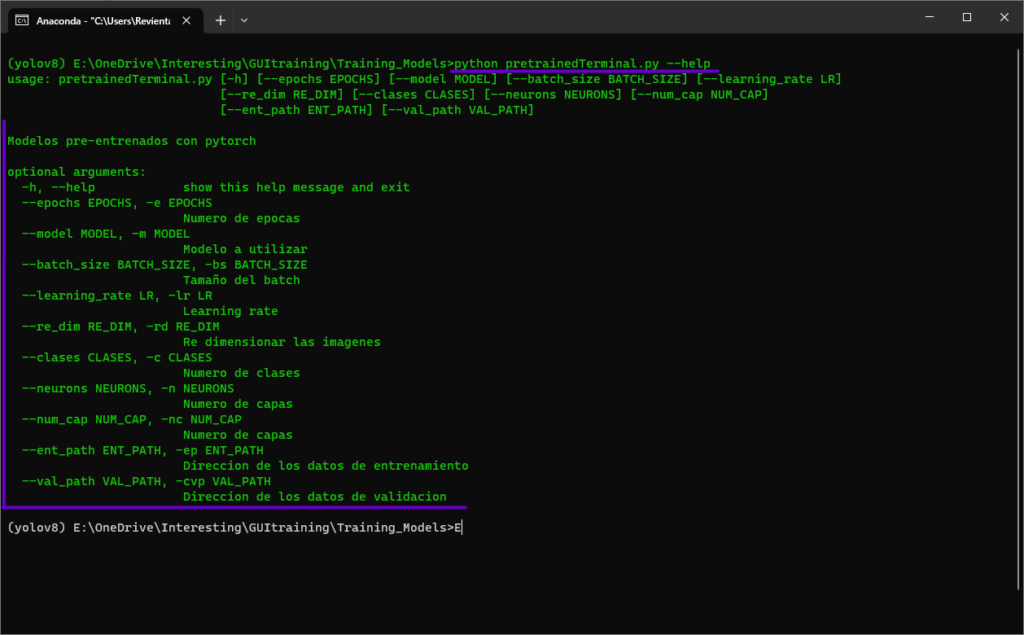
Al utilizar el comando “python pretrainedModels.py –help” como el que se muestra en la imagen, se pueden visualizar las opciones que se pueden modificar en nuestro Script, las cuales son las mismas que se colocaron en nuestra primera función.
Vamos a correr un ejemplo modificando lo mas básico:
-e El número de épocas
-bs El batch size
-c El número de clases
-nc Número de capas ocultas en el clasificador
Como seleccionamos dos capas para el clasificador, el script nos pedirá de cuantas neuronas cada uno. Una vez que le proporcionamos la cantidad de neuronas, el entrenamiento comenzara, que en este caso durara 5 épocas.
Al final podremos ver los resultados de cada época, tanto del entrenamiento como de los datos de validación. Podemos colocar mas métricas para evaluar nuestro modelo, pero eso queda como una mejora al script que pueden realizar como práctica XD.
El código completo esta disponible en nuestro GitHub